Value semantics is a way of organizing your programs, which C++ supports and endorses. Its key characteristics in a nutshell:
- Throughout its lifetime an object (via its type and special member functions) is used to represent a value.
- Different parts of the program communicate values via objects. While the value matters, objects themselves (their address, their
sizeof) do not. - Object’s value is isolated from other objects’ values.
This begs the question, what is value, but we will not answer it. First, because it is difficult, and maybe impossible. It is pretty clear what value objects of type int represent. It is fairly uncontroversial what value is represented by vector<int>, once we accept that the value representation need not fit into the sizeof of the object, but can spread across other memory locations and resources, and that vector’s capacity is not part of this value, even though it is part of its state. But there are things like std::mutex where naming the value is tricky.
(NOTE: If you are interested in the definition of a value, you will find useful links in the References section.)
The second reason is that we do not need to formally distinguish the more platonic value from the more practical object’s state in order to utilize the second and the third property of value semantics above. Let’s reformulate them:
- When communicating the computed state (via objects), object’s identity is irrelevant.
- Object’s state is isolated from other objects’ states.
Let’s illustrate this. Consider the following factory function that returns a unit vector in N-dimensional space, by value:
template <unsigned N>
std::array<int, N> makeUnit()
{
std::array<int, N> ans = {1};
return ans;
}
And another function that uses thus produced value:
int main()
{
std::array unit = makeUnit<6>();
// ...
}
The factory function uses one object ans to build the value. The calling function uses another
object unit to inspect/consume the value. But the only thing that matters is the value that is communicated,
not how many objects are involved in communicating it.
Are they two objects though? Let’s change the example to print their addresses:
template <unsigned N>
std::array<int, N> makeUnit()
{
std::array<int, N> ans = {1};
std::cout << &ans << std::endl;
return ans;
}
int main()
{
std::array unit = makeUnit<6>();
std::cout << &unit << std::endl;
}
Check the results in Compiler Explorer. The two addresses
are identical! It is the same object accessible from two scopes via two different names. But there’s more.
Let’s slightly modify function main to produce a 4-dimensional unit:
template <unsigned N>
std::array<int, N> makeUnit()
{
std::array<int, N> ans = {1};
std::cout << &ans << std::endl;
return ans;
}
int main()
{
std::array unit = makeUnit<4>(); // 4
std::cout << &unit << std::endl;
}
If we now check the results, the addresses differ: we have two objects, only because we changed the size of the array! Is this surprising? If it is, this means you are not abiding by the contract of value semantics. Taking the address of an object returned by value means being interested in the object’s identity rather than the value it represents.
What is the contract, then?
Lets’ first discuss returning by value. The essence of the contract is this: when the called function returns something of a value-semantic type by value, the caller is guaranteed to have the exclusive access to the state represented by the object. No-one else can write or even read the state of the caller’s new object (unless the caller decides otherwise later).
This is nothing surprising for type int:
template <typename T>
T select (T a, T b);
int main()
{
int a = 1;
int b = 2;
int r = select(a, b);
}
It is obvious that once object r enters the stage the only way to change its value is to
call out r explicitly, and because only we have access to the name r, only we can do it.
But it may be less obvious when we replace int with a used-defined type BigInt for storing
arbitrarily big integer numbers, especially for programmers that come from languages like Java,
where the objects of class type are automatically passed by pointer.
int main()
{
BigInt a {"1"};
BigInt b {"2"};
BigInt r = select(a, b);
a.reset();
b.reset();
// is `r` changed?
}
In C++ the answer is simple: r’s state is separate from that of a or b, so modifying the latter
two cannot possibly change the state of r. This guarantee is a big deal for two reasons.
One. There is so many things that you no longer need to concern yourself with: does someone else have access to my state, or can I accidentally change somebody else’s state by modifying my object? In Java to achieve a comparable (but still smaller) level of certainty programmers need to apply the defensive copying technique manually. In C++ when passing value-semantic types by value you get the no-aliasing guarantee automatically. No concurrent access issues, no thread-safety concerns.
Two. The compiler has options to implement such a value-returning convention more efficiently when we all agree that the address of the returned object is irrelevant.
So, what options does the compiler have?
This depends on what kind of type we are dealing with. There are basically four. The first
is like std::mutex, where the state, once created, must remain in one location and never appear in another object.
This is because it is its address that contributes to the essential state. We said earlier that
in the value semantic world the object’s identity must not be observed (in order to avoid surprises as the value travels through objects).
But when an object is statically guaranteed to sit at a single place and never be cloned, in a trivial way, the
stability of the address is guaranteed, and it now becomes part of the object’s state.
It is possible to return such types by value, but we are constrained to only using rvalues inside the factory function:
std::mutex makeMutex()
{
// ...
return std::mutex{}; // rvalue
}
int main()
{
std::mutex m = makeMutex();
// ...
}
An rvalue is something you cannot refer to, because it does not have a name. This way,
we are guaranteed that (modulo intentional hacks) no-one besides the function caller will
read the object’s state, let alone modify it. This is practically the same as
RVO
(return-value optimization) except that it is guaranteed to happen. The way it is
implemented is that the called function knows the location in the caller’s scope where the
destination object needs to be created, and initializes the object exactly in that location.
In the source code, it looks more like makeMutex returns a ‘recipe’ for creating an object,
and the caller is the one who actually creates the object from that recipe.
Note that the following would not compile:
std::mutex makeMutex()
{
std::mutex m;
return m; // error
}
Even though you could reasonably expect an NRVO (named return-value optimization) to occur, NRVO is the compiler’s privilege but by no means a guarantee.
The second kind is trivially-copyable types. These are types like int, std::array<int, 8> or in C++26:
std::inplace_vector<int, 8>. Their entire
state is contained within the sizeof of the object, and their special member functions (copy/move constructors/assignments)
do not do anything but copying bytes. If compiler performs two copies where you expect one, you cannot tell the difference,
so it is allowed to do it under the as-if rule. For such types all the copies and assignments can be implemented with memcpy;
copy construction is equivalent to move construction. When returning by value, the compiler can apply RVO, NRVO, or perform two copies.
We have seen with earlier examples with std::array that compiler decided to go with two different options
only based on different sizes of the array.
The third type is mechanisms, such as std::fstream. Within the scope of their sizeof they store little:
only the file descriptor and maybe a pointer to the temporary buffer. Those are IDs that identify resources
stored elsewhere: in other parts of memory or in the kernel. For value-semantic types, we cannot afford two objects with
overlapping lifetimes to have same resource IDs. However, in the situation where we have to create a new object
and we happen to know that the other object, with the state that we would like to communicate, will no longer be
used – other than being destroyed or reset – we can ‘steal’ its IDs (and therefore state represented by them):
in a transactional manner set the IDs in the target object and set null IDs in the source object.
Before:
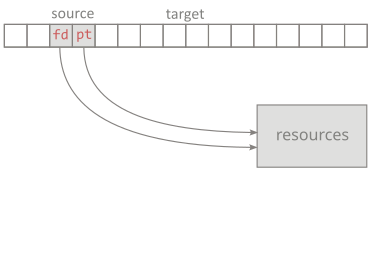
After:
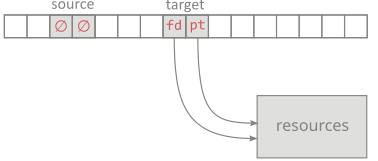
This is the idea behind the move constructor: it requires the type to be able to represent a null state and therefore have a weak invariant.
With a type thus equipped, the compiler has a number of options:
- It still must perform the RVO for rvalues.
- In can perform the NRVO where possible (no move constructor).
- In a number of cases it can create a destination object via the move constructor, when the object name is used in the
return-statement:
std::ofstream log(std::ofstream f)
{
f << data;
return f; // ok: will move
}
std::ofstream logger()
{
// must do RVO:
return std::ofstream{"x.log"};
}
int main()
{
std::ofstream l = log(logger());
// exactly one move-constructor
// ...
}
In the above case, in function log, the contract of returning by value dictates that when this function is invoked and
f returned by value, the move constructor is used for creating the target object, even though f is
clearly not an rvalue (it has a name). It is convenient, and is allowed (required) as it
is assumed that after the return-statement nobody will be able to observe the f’s value.
However, this assumption doesn’t always hold. There are still destructors that need to be called,
and if you are abusing destructors for scope guards,
you may see the moved-from state that you were not expecting.
Sometimes, when a function returns by value, the compiler can refuse to compile, even though you can see that the move constructor would do the job:
std::ofstream fill(std::ofstream in)
{
std::ofstream bk {"backup.log"};
auto& log = cond ? in : bk;
log << data;
return log; // error
}
In that case you can guide the compiler by casting log to an rvalue reference:
return static_cast<std::ofstream&&>(log); // ok
There is a shorter notation for this cast:
return std::move(log);
You should bear in mind, though, that std::move is just a cast, and it does not perform any moving on its own.
But there are cases where a movable type just cannot be returned by value. For instance,
when a to-be-returned object is declared const. While const is a safety feature, it
interferes with move-semantics and the efficient return by value. (At the same time, it prevents
surprises with scope guards.)
Finally, there are types, closely associated with the platonic notion of a value, for which it makes sense to clone the value: given an object, create the second one, storing the same value, but separated, so that modifying the value of one object does not affect the value represented by the other:
std::vector<int> v = {1, 2, 3};
std::vector<int> u = v; // copy (clone)
v.clear();
assert(v.size() == 0);
assert(u.size() == 3);
This is very convenient, but also comes at a cost. In order to guarantee this value separation we need to acquire a separate set of resources where the cloned value can be represented:
Before:

After:

This resource acquisition and the cloning can be a performance hit. In a performance-critical language, providing such an attractive, short syntax for a performance-heavy operation is surprising. Rust’s approach – move by default, clone on demand – seems like a better trade-off.
The cloning/copying operation is performed via the copy constructor. Copyable types usually also provide a more efficient move constructor. Although one could imagine a type that refuses to provide a move constructor in order to avoid weakening the invariant (the null state). In that case the copy constructor is used instead.
This gives the compiler an additional option when a function needs to return something by value.
std::vector<int> getPattern()
{
static const std::vector fallback = {1, 0, 1};
std::vector<int> dyn = getDynamic();
if (matches(dyn))
return dyn; // move
else
return fallback; // copy
}
This all looks complicated, but it gives a simple and a useful guarantee: when you get a value-semantic type returned by value, you get the guarantee of exclusive access to the state represented by the object:
- Nobody else can observe the changes you will make to the state represented by the object.
- Nobody else can change the state represented by your object.
To be continued…
This concludes the first part. In the next parts:
- We will cover passing arguments by value, as it involves different trade-offs.
- See types that are not value semantic.
- See some idioms related to value semantics.
- See how value semantics can be combined with OO-style type erasure.
References
- Alexander Stepanov, Paul McJones, Elements of Programming (book).
- John Lakos, Normative Language to Describe Value Copy Semantics (paper).
- John Lakos, Value Semantics: It ain’t about the syntax! (video).